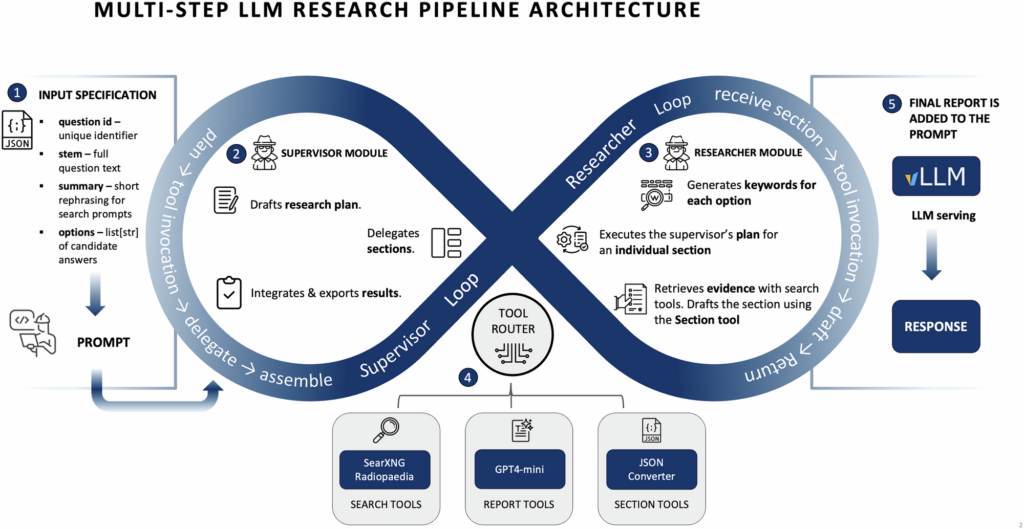
Artificial intelligence (AI) has evolved from performing narrow, specialized tasks to tackling increasingly complex problems that require programming expertise, scientific reasoning, mathematical analysis, and long-term planning. One of the most common ways to evaluate these capabilities is through standardized benchmarks. When an AI model is said to achieve Leads Benchmarks in Code | Research & Multi-step Reasoning, it means the model has demonstrated strong performance across rigorous tests designed to measure its ability to solve challenging problems accurately and consistently.
Benchmark leadership is more than a marketing claim. It reflects meaningful progress in AI capabilities that can benefit software developers, researchers, educators, businesses, and governments. Strong benchmark performance often translates into better real-world applications, including writing reliable code, summarizing large volumes of information, generating research insights, solving mathematical problems, and assisting with strategic decision-making. However, benchmark scores should be interpreted carefully because they measure performance under controlled conditions rather than every possible real-world scenario.
Benchmarks are standardized evaluation datasets and testing frameworks that allow researchers to compare AI systems using the same criteria. They provide objective measurements of how effectively models perform specific tasks and help track progress over time.
Modern AI benchmarks evaluate multiple dimensions of intelligence instead of focusing on a single capability.
Leading benchmark performance generally indicates that an AI system can generalize across a wide variety of tasks rather than memorizing isolated examples.
Software development has become one of the most important applications of modern AI. Coding benchmarks evaluate an AI model’s ability to generate syntactically correct, logically sound, and executable code while following user instructions.
These evaluations often include debugging existing programs, completing unfinished functions, explaining complex algorithms, translating between programming languages, and solving algorithmic challenges.
For example, an AI assistant helping developers build a web application may generate backend APIs, create database schemas, identify security vulnerabilities, and suggest performance improvements—all within a single workflow.
Research-oriented benchmarks measure an AI system’s ability to locate relevant information, synthesize multiple sources, compare viewpoints, and produce coherent analyses. These capabilities are particularly valuable in academic research, business intelligence, healthcare, legal work, and public policy.
Unlike simple question-answering tasks, research often requires connecting ideas across multiple documents, identifying contradictions, evaluating evidence, and presenting balanced conclusions.
A strong research model typically demonstrates the ability to:
These capabilities significantly reduce the time professionals spend reviewing large collections of documents.
Multi-step reasoning refers to solving problems that require a sequence of logical operations rather than a single direct answer. Many real-world tasks involve planning, intermediate calculations, conditional decisions, and revising assumptions based on new information.
For example, designing a supply chain optimization strategy requires analyzing transportation costs, warehouse capacity, production schedules, customer demand, and inventory constraints before arriving at a recommendation.
Similarly, debugging a complex software system may involve identifying the source of an error, testing hypotheses, modifying code, validating outputs, and ensuring that new changes do not introduce regressions.
Organizations increasingly rely on AI systems capable of sustained reasoning across multiple domains.
AI can accelerate development cycles by generating boilerplate code, reviewing pull requests, explaining legacy systems, and assisting with debugging.
Researchers can use AI to review medical literature, organize clinical trial data, identify emerging treatment trends, and summarize evidence while leaving final clinical decisions to qualified professionals.
Financial institutions apply AI to fraud detection, risk assessment, document processing, forecasting, and regulatory compliance.
Students benefit from personalized tutoring, step-by-step explanations, interactive exercises, and adaptive learning experiences.
Scientists use AI to analyze experimental data, generate hypotheses, automate repetitive analyses, and identify patterns within large datasets.
Consider a technology startup building a cloud-based e-commerce platform. Instead of relying solely on manual development, the engineering team uses an AI assistant throughout the software lifecycle.
The AI contributes by generating authentication modules, writing API documentation, suggesting database indexes for performance optimization, identifying inefficient algorithms, creating automated tests, and explaining unfamiliar code to new team members.
As a result, developers spend more time solving business problems rather than repetitive implementation tasks.
A university research team studying renewable energy may need to review thousands of scientific papers spanning multiple disciplines. AI can rapidly organize publications by topic, summarize findings, identify recurring themes, and highlight conflicting evidence.
Rather than replacing researchers, the AI functions as a productivity tool that accelerates literature reviews and supports evidence synthesis. Human experts remain responsible for interpreting results, validating conclusions, and designing experiments.
Although benchmark leadership is valuable, practical usefulness depends on additional factors.
An AI model that performs exceptionally well on academic benchmarks may still require careful oversight when deployed in production environments.
Despite rapid progress, AI systems continue to face important limitations. Models may occasionally generate incorrect information, misunderstand ambiguous instructions, or struggle with highly specialized domains lacking sufficient training data.
Benchmark scores should therefore be viewed as indicators of capability rather than guarantees of flawless performance. Human expertise remains essential for validating outputs in high-stakes contexts such as healthcare, law, engineering, and finance.
Future benchmarking efforts are expected to place greater emphasis on real-world problem solving rather than isolated academic tasks. Emerging evaluation frameworks increasingly measure long-term planning, collaborative reasoning, tool usage, multimodal understanding, and agentic workflows.
Researchers are also developing benchmarks that assess an AI system’s ability to explain its reasoning, acknowledge uncertainty, recover from mistakes, and interact safely with users over extended conversations.
Organizations seeking to benefit from AI systems that perform strongly in coding, research, and reasoning should adopt responsible implementation strategies.
Combining advanced AI capabilities with expert human oversight enables organizations to improve productivity while managing potential risks.
Leading benchmarks in code, research, and multi-step reasoning represent significant milestones in the evolution of artificial intelligence. These achievements demonstrate that modern AI systems are becoming increasingly capable of solving sophisticated problems across software engineering, scientific research, education, finance, healthcare, and many other fields. Strong benchmark performance often correlates with greater productivity, improved decision support, and enhanced collaboration between humans and machines.
At the same time, benchmark leadership should not be viewed as the sole measure of an AI system’s value. Reliability, transparency, safety, adaptability, and responsible deployment remain equally important. The most effective approach combines the speed and analytical power of AI with human judgment, creativity, and domain expertise. As evaluation methods continue to evolve, organizations that understand both the strengths and limitations of AI benchmarks will be best positioned to harness these technologies for innovation and long-term success.