The field of Natural Language Processing (NLP) has undergone a revolutionary transformation over the past decade, largely due to the emergence of Transformer models and their innovative attention mechanisms. From machine translation and text summarization to conversational AI and intelligent search engines, Transformers have become the foundation of modern language understanding systems.
Before the introduction of Transformer architectures, language models relied heavily on recurrent neural networks (RNNs) and long short-term memory networks (LSTMs). While these approaches achieved notable success, they struggled with long-range dependencies, computational efficiency, and scalability. The Transformer model fundamentally changed this landscape by introducing the attention mechanism, enabling machines to process language more effectively and understand context with unprecedented accuracy.
Today, Transformer-based systems power many of the world’s most advanced AI applications. Large language models, intelligent assistants, recommendation systems, and multilingual translation engines all leverage the principles of attention-based learning. Understanding how Transformer attention mechanisms work is essential for anyone interested in artificial intelligence, machine learning, or the future of human-computer interaction.
A Transformer is a deep learning architecture designed specifically to handle sequential data, particularly natural language. Introduced in 2017 through the landmark research paper “Attention Is All You Need,” the Transformer replaced traditional sequential processing methods with a parallelized attention-based approach.
The key innovation of the Transformer lies in its ability to process entire sequences simultaneously rather than word-by-word. This design dramatically improves training speed and allows models to capture complex relationships between words regardless of their position within a sentence.
The architecture consists primarily of two components:
The encoder processes input text and generates contextual representations, while the decoder uses these representations to generate outputs such as translated text, summaries, or responses.
Natural Language Understanding (NLU) refers to a machine’s ability to interpret, analyze, and derive meaning from human language. Early NLP systems relied heavily on manually crafted rules and linguistic frameworks.
These systems faced several limitations:
The introduction of machine learning improved language processing by enabling systems to learn patterns from large datasets. However, traditional neural networks still struggled with understanding long-range relationships in text.
Transformer models addressed these challenges through attention mechanisms that allow the model to focus on relevant information regardless of distance within a sequence.
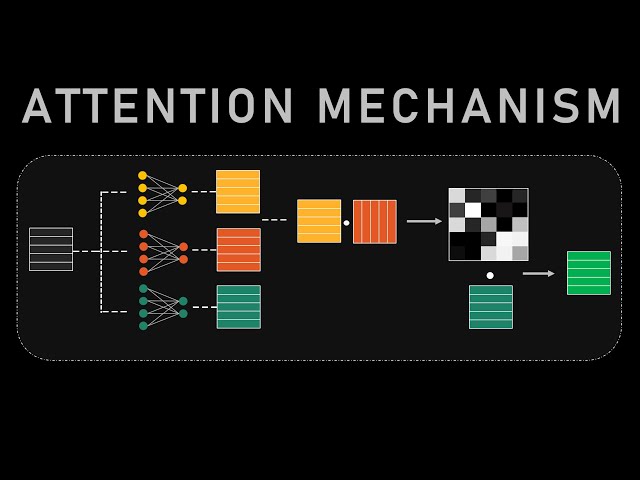
The attention mechanism is the core innovation that makes Transformer models highly effective. At its simplest level, attention allows a model to determine which words in a sentence are most important when interpreting a particular word.
Consider the sentence:
“The animal didn’t cross the street because it was too tired.”
To understand the meaning of “it,” the model must recognize that “it” refers to “the animal” rather than “the street.” Traditional models often struggled with such relationships, especially when relevant words appeared far apart.
The attention mechanism solves this by assigning different importance scores to words within the sequence.
Self-attention is the primary operation within Transformer architectures. It enables each word in a sentence to examine every other word and determine which ones provide useful context.
The process involves three key components:
Each word is transformed into these three representations. The model compares queries with keys to calculate attention scores. These scores determine how much focus should be placed on corresponding values.
The resulting output is a context-aware representation that captures relationships throughout the sentence.
For example, in the sentence:
“The bank approved the loan because it had sufficient funds.”
The model uses attention to determine that “it” refers to “the bank” rather than “the loan.”
While the underlying mathematics can be complex, the core attention formula can be summarized as follows:
Attention(Q,K,V) = Softmax((Q × Kᵀ) / √d) × V
This equation calculates similarity between queries and keys, normalizes the scores, and applies them to values. The result is a weighted representation that emphasizes relevant contextual information.
The scaling factor √d helps maintain numerical stability during training, particularly when working with high-dimensional vectors.
One of the most powerful features of Transformer models is multi-head attention. Instead of computing a single attention pattern, the model performs multiple attention operations simultaneously.
Each attention head learns different aspects of language.
For example:
This parallel analysis enables richer language representations and significantly improves performance across NLP tasks.
Because Transformers process all words simultaneously, they require a mechanism for understanding word order. Positional encoding addresses this challenge by adding positional information to word embeddings.
Without positional encoding, the sentences:
would appear nearly identical to the model.
Positional encoding ensures that sequence information is preserved, allowing the model to distinguish between different sentence structures.
Transformers offer several advantages over traditional RNNs and LSTMs.
These benefits have contributed to widespread adoption across both academia and industry.
Research benchmarks consistently demonstrate that Transformer-based models achieve state-of-the-art results in numerous language understanding tasks.
Machine translation represents one of the most significant success stories of Transformer architectures.
Earlier translation systems often produced awkward or inaccurate results because they struggled to maintain context across long sentences.
Transformers dramatically improved translation quality by considering entire sentence structures simultaneously.
For example, translating a complex paragraph from English to French requires understanding grammatical relationships, verb conjugations, and contextual meanings across multiple clauses.
Attention mechanisms enable the model to identify these relationships effectively, resulting in more natural translations.
Studies have shown that Transformer-based translation systems significantly outperform previous neural translation architectures on standard evaluation benchmarks.
Question-answering systems provide another compelling example of attention-driven language understanding.
Consider the question:
“Who wrote the novel that won the Pulitzer Prize in 1961?”
To answer accurately, the model must connect information across multiple pieces of text and identify relevant entities.
Attention mechanisms allow the model to focus selectively on important portions of the context while ignoring irrelevant information.
This capability has led to substantial improvements in reading comprehension and information retrieval systems.
Large Language Models (LLMs) are built upon Transformer architectures and attention mechanisms. These models are trained on enormous datasets containing billions or even trillions of words.
The attention mechanism allows LLMs to:
The remarkable versatility of modern AI systems stems directly from the capabilities enabled by Transformer-based attention.
One of the greatest achievements of attention-based models is their ability to develop contextual understanding.
Traditional word representations assigned a fixed meaning to each word. However, many words have multiple meanings depending on context.
Consider the word “bank”:
Transformer models use attention to determine the intended meaning based on surrounding words.
This contextual awareness significantly improves language comprehension and reduces ambiguity.
The impact of Transformers on NLP research has been extraordinary.
The architecture has become one of the most influential innovations in modern artificial intelligence.
Although Transformers were originally designed for language tasks, attention mechanisms have proven useful in many other domains.
Vision Transformers (ViTs) apply attention mechanisms to image processing, achieving competitive results with traditional convolutional neural networks.
Transformer models assist in medical diagnosis, clinical document analysis, and drug discovery research.
Financial institutions use attention-based models for market forecasting, risk assessment, and fraud detection.
Attention mechanisms help robots process multimodal information and make context-aware decisions.
Despite their remarkable success, Transformer models face several challenges.
Researchers continue developing more efficient architectures that retain performance while reducing computational overhead.
To address scalability challenges, researchers have proposed numerous enhancements to traditional attention mechanisms.
These innovations aim to improve efficiency while maintaining strong language understanding capabilities.
Some modern architectures can process significantly longer contexts than earlier Transformer models, enabling more sophisticated reasoning over large documents.
The future of NLU will likely involve increasingly sophisticated attention mechanisms capable of handling multimodal information, reasoning across extensive contexts, and interacting with external knowledge sources.
Emerging trends include:
As computational resources and research methodologies continue to advance, Transformer-based systems are expected to achieve even deeper levels of language understanding.
The attention mechanism allows a model to determine which words or tokens are most relevant when interpreting a specific part of a sentence, improving contextual understanding.
Transformers process sequences in parallel, capture long-range dependencies more effectively, and scale better to large datasets and complex tasks.
Self-attention enables each word in a sequence to evaluate relationships with every other word, creating context-aware representations.
Multi-head attention performs multiple attention calculations simultaneously, allowing the model to learn different linguistic relationships at the same time.
They capture context, semantic relationships, and long-distance dependencies more effectively than previous architectures, leading to superior language comprehension.
Yes. Attention-based architectures are widely applied in computer vision, robotics, healthcare, finance, scientific research, and many other fields.
The Transformer model and its attention mechanism represent one of the most significant breakthroughs in artificial intelligence and natural language understanding. By enabling machines to focus selectively on relevant information and process entire sequences simultaneously, attention mechanisms have overcome many of the limitations that constrained earlier neural network architectures.
From machine translation and question answering to conversational AI and large language models, Transformers have redefined what is possible in language processing. Their ability to capture context, understand semantic relationships, and scale effectively has made them the foundation of modern AI systems. Beyond language, attention-based architectures are now influencing fields such as computer vision, healthcare, robotics, and finance, demonstrating their remarkable versatility.
As research continues to improve efficiency, scalability, and interpretability, Transformer-based models will remain at the forefront of AI innovation. Understanding the attention mechanism is therefore not only essential for NLP practitioners but also for anyone seeking to understand the technologies shaping the future of intelligent systems. The success of Transformers illustrates a powerful lesson in artificial intelligence: sometimes, the ability to pay attention is the key to understanding.